前言:这里是我记录的常见(面试和日常)知识点,方便记忆和学习
[译]Node.js 框架比较( Express vs. Koa vs. Hapi )
1 介绍
Express.js无疑是当前Node.js中最流行的Web应用程序框架。它几乎成为了大多数Node.js web应用程序的基本的依赖,甚至一些例如Sails.js这样的流行的框架也是基于Express.js。然而你还有一些其他框架的选择,可以给你带来“sinatra”一样的感觉(译注:sinatra是一个简单的Ruby的Web框架,可以参考这篇博文)。另外两个最流行的框架分别是Koa和Hapi。
这篇文章不是打算说服你哪个框架比另外一个更好,而是只是打算让你更好地理解每个框架能做什么,什么情况下一个框架可以秒杀另外一个。
2 框架的背景
我们将要探讨的两个框架看起来都非常相似。每一个都能够用几行代码来构建一个服务器,并都可以非常轻易地构建REST API。我们先瞧瞧这几个框架是怎么诞生的。
2.1 Express
2009年6月26日,TJ Holowaychuk提交了Express的第一次commit,接下来在2010年1月2日,有660次commits的Express 0.0.1版本正式发布。TJ和Ciaron Jessup是当时最主要的两个代码贡献者。在第一个版本发布的时候,根据github上的readme.md,这个框架被描述成:
疯一般快速(而简洁)的服务端JavaScript Web开发框架,基于Node.js和V8 JavaScript引擎。
差不多5年的时间过去了,Express拥有了4,925次commit,现在Express的最新版本是4.10.1,由StrongLoop维护,因为TJ现在已经跑去玩Go了。
2.2 Koa
大概在差不多一年前的2013年8月17日,TJ Holowaychuk(又是他!)只身一人提交了Koa的第一次commit。他描述Koa为“表现力强劲的Node.js中间件,通过co使用generators使得编写web应用程序和REST API更加丝般顺滑”。Koa被标榜为只占用约400行源码空间的框架。Koa的目前最新版本为0.13.0,拥有583次commits。
2.3 Hapi
2011年8月5日,WalmartLabs的一位成员Eran Hammer提交了Hapi的第一次commit。Hapi原本是Postmile的一部分,并且最开始是基于Express构建的。后来它发展成自己自己的框架,正如Eran在他的博客里面所说的:
Hapi基于这么一个想法:配置优于编码,业务逻辑必须和传输层进行分离..
Hapi最新版本为7.2.0,拥有3,816次commits,并且仍然由Eran Hammer维护。
3 创建一个服务器
所有开发者要开发Node.js web应用程序的第一步就是构建一个基本的服务器。所以我们来看看用这几个框架构建一个服务器的时候有什么异同。
3.1 Express
1 | var express = require('express'); |
对于所有的node开发者来说,这看起来相当的自然。我们把express require进来,然后初始化一个实例并且赋值给一个为app的变量。接下来这个实例初始化一个server监听特定的端口,3000端口。app.listen()函数实际上包装了node原生的http.createServer()函数。
3.2 Koa
1 | var koa = require('koa'); |
你马上发现Koa和Express是很相似的。其实差别只是你把require那部分换成koa而不是express而已。app.listen()也是和Express一模一样的对原生代码的封装函数。
3.3 Hapi
1 | var Hapi = require('hapi'); |
Hapi是三者中最独特的一个。和其他两者一样,hapi被require进来了但是没有初始化一个hapi app而是构建了一个server并且指定了端口。在Express和Koa中我们得到的是一个回调函数而在hapi中我们得到的是一个新的server对象。一旦我们调用了server.start()我们就开启了端口为3000的服务器,并且返回一个回调函数。这个server.start()函数和Koa、Express不一样,它并不是一个http.CreateServer()的包装函数,它的逻辑是由自己构建的。
4 路由控制
现在一起来搞搞一下服务器最重要的特定之一,路由控制。我们先用每个框架分别构建一个老掉渣的“Hello world”应用程序,然后我们再探索一下一些更有用的东东,REST API。
4.1 Hello world
4.1.1 Express
1 | var express = require('express'); |
我们用get()函数来捕获“GET /”请求然后调用一个回调函数,这个回调函数会被传入req和res两个对象。这个例子当中我们只利用了res的res.send()来返回整个页面的字符串。Express有很多内置的方法可以用来进行路由控制。get, post, put, head, delete等等这些方法都是Express支持的最常用的方法(这只是一部分而已,并不是全部)。
4.1.2 Koa
1 | var koa = require('koa'); |
Koa和Express稍微有点儿不同,它用了ES6的generators(不懂得话请参考generators学习)。所有带有*前缀的函数都表示这个函数会返回一个generator对象。根本上来说,generator会同步地yield出数据(译注:如果对Python比较熟悉的话,应该对ES6的generator不陌生,这里的yield其实和Python的yield语句差不多一个意思),这个超出本文所探索的内容,不详述。在app.use()函数中,generator函数设置响应体。在Koa中,this这个上下文其实就是对node的request和response对象的封装。this.body是KoaResponse对象的一个属性。this.body可以设置为字符串, buffer, stream, 对象, 或者null也行。上面的例子中我们使用了Koa为数不多的中间件的其中一个。这个中间件捕获了所有的路由并且响应同一个字符串。
4.1.3 Hapi
1 | var Hapi = require('hapi'); |
这里使用了server对象给我们提供的server.route内置的方法,这个方法接受配置参数:path(必须),method(必须),vhost,和handler(必须)。HTTP方法可以处理典型的例如GET、PUT、POST、DELETE的请求,*通配符可以匹配所有的路由。handler函数被传入一个request对象的引用,它必须调用reply函数包含需要返回的数据。数据可以是字符串、buffer、可序列化对象、或者stream。
4.2 REST API
Hello world除了给我们展示了如何让一个应用程序运行起来以外几乎啥都没干。在所有的重数据的应用程序当中,REST API几乎是一个必须的设计,并且能让我们更好地理解这些框架是可以如何使用的。现在让我们看看这些框架是怎么处理REST API的。
4.2.1 Express
1 | var express = require('express'); |
我们为已有的Hello World应用程序添加REST API。Express提供一些处理路由的便捷的方式。这是Express 4.x的语法,除了你不需要express.Router()和不能用app.user(‘/api’, router)以外,其实上是和Express 3.x本质上是一样的。在Express 3.x中,你需要用app.route()替换router.route()并且需要加上/api前缀。Express 4.x的这种语法可以减少开发者编码错误并且你只需要修改少量代码就可以修改HTTP方法规则。
4.2.2 Koa
1 | var koa = require('koa'); |
很明显,Koa并没有类似Express这样的可以减少编码重复路由规则的能力。它需要额外的中间件来处理路由控制。我选择使用koa-route因为它是由Koa团队维护的,但是还有很多由其他开发者维护的可用的中间件。Koa的路由和Express一样使用类似的关键词来定义它们的方法,.get(), .put(),.post(), 和 .delete()。Koa在处理路由的时候有一个好处就是,它使用ES6的generators函数来减少对回调函数的处理。
4.2.3 Hapi
1 | var Hapi = require('hapi'); |
对于Hapi路由处理的第一印象就是,相对于其它两个框架,这货是多么的清爽,可读性是多么的棒!即使是那些必须的method,path,handler和reply配置参数都是那么的赏心悦目(译注:作者高潮了)。类似于Koa,Hapi很多重复的代码会导致更大的出错多可能性。然而这是Hapi的有意之为,Hapi更关注配置并且希望使得代码更加清晰和让团队开发使用起来更加简便。Hapi希望可以不需要开发者进行编码的情况下对错误处理进行优化。如果你尝试去访问一个没有被定义的REST API,它会返回一个包含状态码和错误的描述的JSON对象。
5 优缺点比较
5.1 Express
5.1.1 优点
Express拥有的社区不仅仅是上面三者当中最大的,并且是所有Node.js web应用程序框架当中最大的。在经过其背后差不多5年的发展和在StrongLoop的掌管下,它是三者当中最成熟的框架。它为服务器启动和运行提供了简单的方式,并且通过内置的路由提高了代码的复用性。
5.1.2 缺点
使用Express需要手动处理很多单调乏味的任务。它没有内置的错误处理。当你需要解决某个特定的问题的时候,你会容易迷失在众多可以添加的中间件中,在Express中,你有太多方式去解决同一个问题。Express自诩为高度可配置,这有好处也有坏处,对于准备使用Express的刚入门的开发者来说,这不是一件好的事情。并且对比起其他框架来说,Express体积更大。
5.2 Koa
5.2.1 优点
Koa有着傲人的身材(体积小),它表现力更强;对比起其他框架,它使得中间件的编写变的更加容易。Koa基本上就是一个只有骨架的框架,你可以选择(或者自己写一个)中间件,而不用妥协于Express或者Hapi它们自带的中间件。它也是唯一一个采用ES6的框架,例如它使用了ES6的generators。
5.2.2 缺点
Koa不稳定,仍处于活跃的开发完善阶段。使用ES6还是有点太超前了,例如只有0.11.9+的Node.js版本才能运行Koa,而现在最新的Node.js稳定版本是0.10.33。和Express一样有好也有坏的一点就是,在多种中间件的选择还是自己写中间件。就像我们之前所用的router那样,有太多类似的router中间件可供我们选择。
5.3 Hapi
5.3.1 优点
Hapi自豪地宣称它自己是基于配置优于编码的概念,并且很多开发者认为这是一件好事。在团队项目开发中,可以很容易地增强一致性和可复用性。作为有着大名鼎鼎的WalmartLabs支持的框架和其他响当当的企业在实际生产中使用Hapi,它已经经过了实际战场的洗礼,企业们可以没有担忧地基于Hopi运行自己的应用程序。所有的迹象都表明Hapi向着成为的伟大的框架的方向持续成熟。
5.3.2 缺点
Hapi绝逼适合用来开发更大更复杂的应用。但对于一个简单的web app来说,它的可能有点儿堆砌太多样板代码了。而且Hapi的可供参考样例太少了,或者说开源的使用Hapi的应用程序太少了。所以选择它对开发者的要求更高一点,而不是所使用的中间件。
6 总结
我们已经看过三个框架一些棒棒的而且很实际的例子了。Express毫无疑问是三个当中最流行和最出名的框架。当你要开发一个新的应用程序的时候,使用Express来构建一个服务器可能已经成为了你的条件反射了;但希望现在你在做选择的时候会多一些思考,可以考虑选择Koa或者Hapi。Koa通过超前拥抱ES6和Web component的思想,显示了Web开发社区正在进步的对未来的承诺。对于比较大的团队和比较大的项目来说,Hapi应该成为首要选择。它所推崇的配置优于编码,对团队和对团队一直追求的可复用性都大有裨益。现在赶紧行动起来尝试使用一个新的框架,可能你会喜欢或者讨厌它,但没到最后你总不会知道结果是怎么样的,有一点无容置疑的是,它会让你成为一个更好的开发者。
【转载】七个对我最重要的职业建议(译文)
—————–Nicholas C. Zakas 是全世界最著名的 JavaScript 程序员之一。
两年前,他写了一篇长文,回顾自己的职业生涯,提到七个对他来说最重要的建议。

我读完很受启发,决定做一点摘录。你可以先读下面的精简版,再去读全文。
一、不要别人点什么,就做什么
我的第一份工作,只干了8个月,那家公司就倒闭了。我问经理,接下来我该怎么办,他说:
小伙子,千万不要当一个被人点菜的厨师,别人点什么,你就烧什么。不要接受那样一份工作,别人下命令你该干什么,以及怎么干。你要去一个地方,那里的人肯定你对产品的想法,相信你的能力,放手让你去做。
我从此明白,单单实现一个产品是不够的,你还必须参与决定怎么实现。好的工程师并不仅仅服从命令,而且还给出反馈,帮助产品的拥有者改进它。
二、推销自己
我进入雅虎公司以后,经理有一天跟我谈话,他觉得我还做得不够。
你工作得很好,代码看上去不错,很少出Bug。但是,问题是别人都没看到这一点。为了让其他人相信你,你必须首先让别人知道你做了什么。你需要推销自己,引起别人的注意。
我这才意识到,即使做出了很好的工作,别人都不知道,也没用。做一个角落里静静编码的工程师,并不可取。你的主管会支持你,但是他没法替你宣传。公司的其他人需要明白你的价值,最好的办法就是告诉别人你做了什么。一封简单的Email:”嗨,我完成了XXX,欢迎将你的想法告诉我”,就很管用。
三、学会带领团队
工作几年后,已经没人怀疑我的技术能力了,大家知道我能写出高质量的可靠代码。有一次,我问主管,怎么才能得到提升,他说:
当你的技术能力过关以后,就要考验你与他人相处的能力了。
于是,我看到了,自己缺乏的是领导能力,如何带领一个团队,有效地与其他人协同工作,取到更大的成果。
四、生活才是最重要的
有一段时间,我在雅虎公司很有挫折感,对公司的一些做法不认同,经常会对别人发火。我问一个同事,他怎么能对这种事情保持平静,他回答:
你要想通,这一切并不重要。有人提交了烂代码,网站下线了,又怎么样?工作并不是你的整个生活。它们不是真正的问题,只是工作上的问题。真正重要的事情都发生在工作以外。我回到家,家里人正在等我,这才重要啊。
从此,我就把工作和生活分开了,只把它当作”工作问题”看待。这样一来,我对工作就总能心平气和,与人交流也更顺利了。
五、自己找到道路
我被提升为主管以后,不知道该怎么做。我请教了上级,他回答:
以前都是我们告诉你做什么,从现在开始,你必须自己回答这个问题了,我期待你来告诉我,什么事情需要做。
很多工程师都没有完成这个转变,如果能够做到,可能就说明你成熟了,学会了取舍。你不可能把时间花在所有事情上面,必须找到一个重点。
六、把自己当成主人
我每天要开很多会,有些会议我根本无话可说。我对一个朋友说,我不知道自己为什么要参加这个会,也没有什么可以贡献,他说:
不要再去开这样的会了。你参加一个会,那是因为你参与了某件事。如果不确定自己为什么要在场,就停下来问。如果这件事不需要你,就离开。不要从头到尾都静静地参加一个会,要把自己当成负责人,大家会相信你的。
从那时起,我从没有一声不发地参加会议。我确保只参加那些需要我参加的会议。
七、找到水平更高的人
最后,让我从自己的经历出发,给我的读者一个建议。
找到那些比你水平更高、更聪明的人,尽量和他们在一起,吃饭或者喝咖啡,向他们讨教,了解他们拥有的知识。你的职业,甚至你的生活,都会因此变得更好。
js字符编码函数区别分析
今天leaf用ajax发送请求,服务端返回的其他字段内容都OK,但是处理中文名称的图片服务端返回来格式正确但是字段名称是乱码(英文是OK的哈,但leaf想尝试中文),于是对于解决传值乱码问题yujuan查了资料,把内容总结如下:
JavaScript中有三个可以对字符串编码的函数,分别是:
1 |
|
详解js的3个对文字编码的函数: escape,encodeURI,encodeURIComponent, 对应的解码函数:unescape,decodeURI,decodeURIComponent
一、定义和用法
encodeURI() 函数可把字符串作为 URI 进行编码。
语法
encodeURI(URIstring)
| 参数 | 描述 |
|---|---|
| URIstring | 必需。一个字符串,含有 URI 或其他要编码的文本。 |
返回值
URIstring 的副本,其中的某些字符将被十六进制的转义序列进行替换。
说明
该方法不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号进行编码: - _ . ! ~ * ‘ ( ) 。
该方法的目的是对 URI 进行完整的编码,因此对以下在 URI 中具有特殊含义的 ASCII 标点符号,encodeURI() 函数是不会进行转义的:;/?:@&=+$,#
提示和注释
提示:如果 URI 组件中含有分隔符,比如 ? 和 #,则应当使用 encodeURIComponent() 方法分别对各组件进行编码。
此方法的解码为decodeURI()
二、定义和用法
escape() 函数可对字符串进行编码,这样就可以在所有的计算机上读取该字符串。
语法
escape(string)
| 参数 | 描述 |
|---|---|
| string | 必需。要被转义或编码的字符串。 |
返回值
已编码的 string 的副本。其中某些字符被替换成了十六进制的转义序列。
说明
该方法不会对 ASCII 字母和数字进行编码,也不会对下面这些 ASCII 标点符号进行编码: - _ . ! ~ * ‘ ( ) 。其他所有的字符都会被转义序列替换。
提示和注释
提示:可以使用 unescape() 对 escape() 编码的字符串进行解码。
注释:ECMAScript v3 反对使用该方法,应用使用 decodeURI() 和 decodeURIComponent() 替代它。
三、JavaScript encodeURIComponent() 函数
定义和用法
encodeURIComponent() 函数可把字符串作为 URI 组件进行编码。
语法
encodeURIComponent(URIstring)
| 参数 | 描述 |
|---|---|
| URIstring | 必需。一个字符串,含有 URI 组件或其他要编码的文本。 |
返回值
URIstring 的副本,其中的某些字符将被十六进制的转义序列进行替换。
说明
该方法不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号进行编码: - _ . ! ~ * ‘ ( ) 。
其他字符(比如 :;/?:@&=+$,# 这些用于分隔 URI 组件的标点符号),都是由一个或多个十六进制的转义序列替换的。
提示和注释
提示:请注意 encodeURIComponent() 函数 与 encodeURI() 函数的区别之处,前者假定它的参数是 URI 的一部分(比如协议、主机名、路径或查询字符串)。因此 encodeURIComponent() 函数将转义用于分隔 URI 各个部分的标点符号。
此方法解码方式decodeURIComponent
js二叉树遍历
这篇文章主要为大家详细介绍了JS中的二叉树遍历,何为二叉树,什么是二叉树的遍历,感兴趣的小伙伴们可以参考一下
二叉树是由根节点,左子树,右子树组成,左子树和友子树分别是一个二叉树。
递归广度优先遍历 二叉树
广度优先搜索算法(Breadth First Search),又叫宽度优先搜索,或横向优先搜索。
广度优先遍历是从二叉树的第一层(根结点)开始,自上至下逐层遍历;在同一层中,按照从左到右的顺序对结点逐一访问。
是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。
如右图所示的二叉树: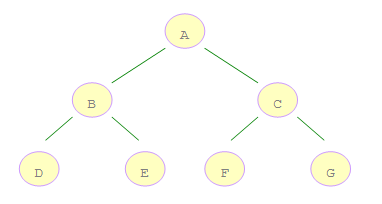
A 是第一个访问的,然后顺序是 B、C,然后再是 D、E、F、G。
那么,怎样才能来保证这个访问的顺序呢?
借助队列数据结构,由于队列是先进先出的顺序,因此可以先将左子树入队,然后再将右子树入队。
这样一来,左子树结点就存在队头,可以先被访问到。
实现:
nodejs递归创建多层目录
在nodejs官方API中只提供了最基本的方法,只能创建单级目录,如果要创建一个多级的目录(./aaa/bbb/ccc)就只能一级一级的创建,
感觉不是很方便,因此简单写了两个支持多级目录创建的方法。nodejs递归创建目录,同步和异步方法。
Javascript代码
1 |
|
zepto的tap事件点透分析
移动端WEB开发中,click 和 tap两者都会在点击时触发,但是click会有 200~300 ms,所以请用tap代替click作为点击事件。但是在使用zepto框架的tap来模拟移动设备浏览器内的点击事件,来规避click事件的延迟响应时,有可能出现点透的情况,即点击会触发非当前层的点击事件。
zepto的tap事件点透问题分析:
一、“点透”是什么
你可能碰到过在列表页面上创建一个弹出层,弹出层有个关闭的按钮,你点了这个按钮关闭弹出层后后,这个按钮正下方的内容也会执行点击事件(或打开链接)。这个被定义为这是一个“点透”现象。
比如在项目中遇到了如下图的问题:在点击弹出来的选择组件的右上角完成后会让完成后面的input输入框聚焦,弹出输入键盘,也就是点透了。
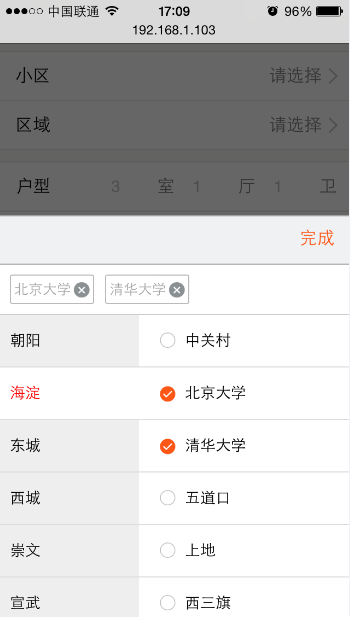
二、为什么会出现点透呢?
这个需要从zepto(或者jqm)源码里面看关于tap的实现方法:
1 |
|
1、可以看出zepto的tap通过兼听绑定在document上的touch事件来完成tap事件的模拟的,及tap事件是冒泡到document上触发的
2、再点击完成时的tap事件(touchstart\touchend)需要冒泡到document上才会触发,而在冒泡到document之前,用户手的接触屏幕(touchstart)和离开屏幕(touchend)是会触发click事件的,因为click事件有延迟触发(这就是为什么移动端不用click而用tap的原因)(大概是300ms,为了实现safari的双击事件的设计),所以在执行完tap事件之后,弹出来的选择组件马上就隐藏了,此时click事件还在延迟的300ms之中,当300ms到来的时候,click到的其实不是完成而是隐藏之后的下方的元素,如果正下方的元素绑定的有click事件此时便会触发,如果没有绑定click事件的话就当没click,但是正下方的是input输入框(或者select选择框或者单选复选框),点击默认聚焦而弹出输入键盘,也就出现了上面的点透现象。
三、zepto方案tap事件的问题?
1、因为js标准本不支持tap事件,所以zepto tap是touchstart与touchend模拟而出
2、zepto在初始化时便给document绑定touch事件,在我们点击时根据event参数获得当前元素,并会保存点下和离开时候的鼠标位置
3、根据当前元素鼠标移动范围判断是否为类点击事件,如果是便触发已经注册好的tap事件
4、zepto的代码里面有个settimeout,因为settimeout会将优先级降低(相见setTimeout详解),有了定时器,当代码执行到setTimeout的时候, 就会把这个代码放到JS的引擎的最后面,这就是为什么一旦加入settimeout,e.preventDefault便不会生效
点透的解决方法:
方案一:来得很直接github上有个fastclick可以完美解决https://github.com/ftlabs/fastclick
引入fastclick.js,因为fastclick源码不依赖其他库所以你可以在原生的js前直接加上
1 | 1 window.addEventListener( "load", function() { |
或者有zepto或者jqm的js里面加上
1 | 1 $(function() { |
当然require的话就这样:
1 | 1 var FastClick = require(‘fastclick‘); |
方案二:用touchend代替tap事件并阻止掉touchend的默认行为preventDefault()
1 | 1 $("#cbFinish").on("touchend", function (event) { |
方案三:延迟一定的时间(300ms+)来处理事件
1 | 1 $("#cbFinish").on("tap", function (event) { |
这种方法其实很好,可以和fadeInIn/fadeOut等动画结合使用,可以做出过度效果
理论上上面的方法可以完美的解决tap的点透问题,如果真的倔强到不行,用click
setTimeout详解
setTimeout,前端工程师必定会打交道的一个函数。它看上去非常的简单,朴实。有着一个很不平凡的名字–定时器。但它隐含着惊天大密。
要说setTimeout的渊源,就得从它的官方定义说起。w3c是这么定义的:
setTimeout() 方法用于在指定的毫秒数后调用函数或计算表达式。
看到这样一个说明,我们明白了它就是一个定时器,我们设定的函数就是一个”闹钟”,时间到了它就会去执行.然而聪明的你不禁有这样一个疑问,如果是settimeout(fn,0)呢?按照定义的说明,它是否会立马执行?实践是检验真理的唯一标准,让我们来看看下面的实验。
1 |
|
这是一个很简单的实验,如果settimeout(0)会立即执行,那么这里的执行结果就应该是1->2>3 。 然而实际的结果却是1->3->2。 这说明了settimeout(0)并不是立即执行。同时让我们对settimeout的行为感到很诡异。
js引擎是单线程执行的
我们先把上面的问题放一放.从js语言的设计上来看看是否能找到蛛丝马迹。
我们发现js语言设计的一个很重要的点是,js是没有多线程的.js引擎的执行是单线程执行.这个特性曾经困扰我很久,我想不明白既然js是单线程的,那么是谁来为定时器计时的?是谁来发送ajax请求的?我陷入了一个盲区。即将js等同于浏览器。我们习惯了在浏览器里面执行代码,却忽略了浏览器本身。js引擎是单线程的,可是浏览器却可以是多线程的,js引擎只是浏览器的一个线程而已.定时器计时,网络请求,浏览器渲染等等。都是由不同的线程去完成的。 口说无凭,咱们依然看一个例子:
1 |
|
isEnd默认是true的,在while中是死循环的。最后的alert是不会执行的。 我添加了一个定时器,1秒后将isEnd改为false。 如果说js引擎是多线程的,那么在1秒后,alert就会被执行.然而实际情况是,页面会永远死循环下去。alert并没有执行.这很好的证明了,settimeout并不能作为多线程使用。js引擎执行是单线程的。
event loop
从上面的实验中,我们更加疑惑了,settimeout到底做了什么事情呢?
原来还是得从js语言的设计上寻找答案。
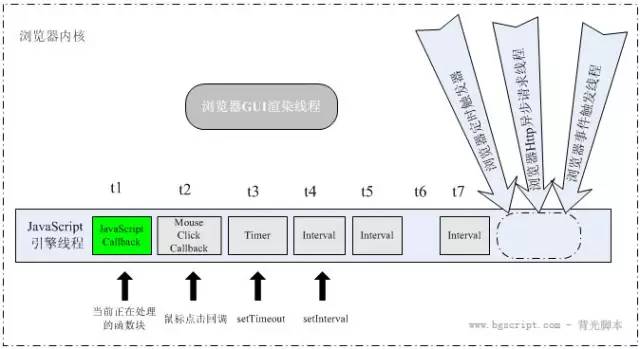
js引擎单线程执行的,它是基于事件驱动的语言。它的执行顺序是遵循一个叫做事件队列的机制。从图中我们可以看出,浏览器有各种各样的线程,比如事件触发器,网络请求,定时器等等.线程的联系都是基于事件的。js引擎处理到与其他线程相关的代码,就会分发给其他线程,他们处理完之后,需要js引擎计算时就是在事件队列里面添加一个任务。 这个过程中,js并不会阻塞代码等待其他线程执行完毕,而且其他线程执行完毕后添加事件任务告诉js引擎执行相关操作。这就是js的异步编程模型。
如此我们再回过头来看settimeout(0)就会恍然大悟。js代码执行到这里时,会开启一个定时器线程,然后继续执行下面的代码。该线程会在指定时间后往事件队列里面插入一个任务.由此可知settimeout(0)里面的操作会放在所有主线程任务之后。 这也就解释了为什么第一个实验结果是1->3-2 。
由此可见官方对于settimeout的定义是有迷惑性的。应该给一个新的定义:
在指定时间内, 将任务放入事件队列,等待js引擎空闲后被执行。
js引擎与GUI引擎是互斥的
谈到这里,就不得不说浏览器的另外一个引擎—GUI渲染引擎。 在js中渲染操作也是异步的。比如dom操作的代码会在事件队列中生成一个任务,js执行到这个任务时就会去调用GUI引擎渲染。
js语言设定js引擎与GUI引擎是互斥的,也就是说GUI引擎在渲染时会阻塞js引擎计算。原因很简单,如果在GUI渲染的时候,js改变了dom,那么就会造成渲染不同步. 我们需要深刻理解js引擎与GUI引擎的关系,因为这与我们平时开发息息相关,我们时长会遇到一些很奇葩的渲染问题。看这个例子。
1 |
|
我们希望能看到计算的每一个过程,我们在程序开始,计算,结束时,都执行了一个dom操作,插入了代表当前状态的字符串,Not Calculating yet.和calculating….和calclation done.计算中是一个耗时的3重for循环. 在没有使用settimeout的时候,执行结果是由Not Calculating yet 直接跳到了calclation done.这显然不是我们希望的。而造成这样结果的原因正是js的事件循环单线程机制.dom操作是异步的,for循环计算是同步的。异步操作都会被延迟到同步计算之后执行。也就是代码的执行顺序变了。calculating….和calclation done的dom操作都被放到事件队列后面而且紧跟在一起,造成了丢帧.无法实时的反应。这个例子也告诉了我们,在需要实时反馈的操作,如渲染等,和其他相关同步的代码,要么一起同步,要么一起异步才能保证代码的执行顺序。在js中,就只能让同步代码也异步.即给for计算加上settimeout。
settimeout(0)的作用
不同浏览器的实现情况不同,HTML5定义的最小时间间隔是4毫秒。 使用settimeout(0)会使用浏览器支持的最小时间间隔.所以当我们需要把一些操作放到下一帧处理的时候,我们通常使用settimeout(0)来hack。
requestAnimationFrame
这个函数与settimeout很相似,但它是专门为动画而生的。settimeout经常被用来做动画。我们知道动画达到60帧,用户就无法感知画面间隔。每一帧大约16毫秒。而requestAnimationFrame的帧率刚好是这个频率。除此之外相比于settimeout,还有以下的一些优点:
requestAnimationFrame 会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率,一般来说,这个频率为每秒60帧,每帧大约16毫秒。
在隐藏或不可见的元素中,requestAnimationFrame将不会进行重绘或回流,这当然就意味着更少的的cpu,gpu和内存使用量。
但它优于setTimeout/setInterval的地方在于它是由浏览器专门为动画提供的API,在运行时浏览器会自动优化方法的调用,并且如果页面不是激活状态下的话,动画会自动暂停,有效节省了CPU开销。
总结:
浏览器的内核是多线程的,它们在内核制控下相互配合以保持同步,一个浏览器至少实现三个常驻线程:javascript引擎线程,GUI渲染线程,浏览器事件触发线程。
javascript引擎是基于事件驱动单线程执行的。JS引擎一直等待着任务队列中任务的到来,然后加以处理,浏览器无论什么时候都只有一个JS线程在运行JS程序。
当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行。但需要注意 GUI渲染线程与JS引擎是互斥的,当JS引擎执行时GUI线程会被挂起,GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
当一个事件被触发时该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理。这些事件可来自JavaScript引擎当前执行的代码块如setTimeOut、也可来自浏览器内核的其他线程如鼠标点击、AJAX异步请求等,但由于JS的单线程关系所有这些事件都得排队等待JS引擎处理。