这篇文章主要为大家详细介绍了JS中的二叉树遍历,何为二叉树,什么是二叉树的遍历,感兴趣的小伙伴们可以参考一下
二叉树是由根节点,左子树,右子树组成,左子树和友子树分别是一个二叉树。
递归广度优先遍历 二叉树
广度优先搜索算法(Breadth First Search),又叫宽度优先搜索,或横向优先搜索。
广度优先遍历是从二叉树的第一层(根结点)开始,自上至下逐层遍历;在同一层中,按照从左到右的顺序对结点逐一访问。
是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。
如右图所示的二叉树: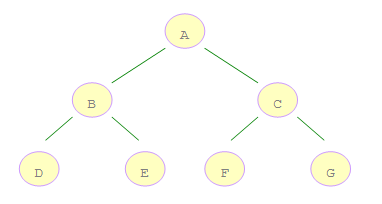
A 是第一个访问的,然后顺序是 B、C,然后再是 D、E、F、G。
那么,怎样才能来保证这个访问的顺序呢?
借助队列数据结构,由于队列是先进先出的顺序,因此可以先将左子树入队,然后再将右子树入队。
这样一来,左子树结点就存在队头,可以先被访问到。
实现:
使用数组模拟队列。首先将根节点归入队列。当队列不为空的时候,执行循环:取出队列的一个节点,如果该结点的左子树为非空,则将该结点的左子树入队列;如果该结点的右子树为非空,则将该结点的右子树入队列。
Javascript代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
var tree= {
value: 'd',
left: {
value: 'o',
left: {
value: 'g',
left: {
value: 'n',
left: {
value: 'o',
left: {
value: 'd',
left: {value: 'e'}
},
},
},
right: {value: 'a'}
},
right: {
value: 'r',
left: {value: 'n'},
right: {value: '2'}
}
},
right: {
value: 'n',
left: {
value: 'u',
left: {value: '0'},
right: {
value: '1'
}
},
right: {
value: 'i',
left: {value: '6'},
right: {
value: 'n'
}
}
}
};
function levelOrderTraversal(node){
if(!node){
return console.log('该树是一个空树');
};
var TempAry=[],ary=[];
TempAry.push(node);
while(TempAry.length!==0){
node = TempAry.shift();
ary.push(node.value);
if(node.left){TempAry.push(node.left)}
if(node.right){TempAry.push(node.right)}
}
console.log('广度优先遍历:'+ary.join(''));
}
levelOrderTraversal(tree);
|
递归深度优先遍历 二叉树
深度优先搜索算法(Depth First Search),是搜索算法的一种。是沿着树的深度遍历树的节点,尽可能深的搜索树的分支。
当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。
如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
如右图所示的二叉树:
A 是第一个访问的,然后顺序是 B、D,然后是 E。接着再是 C、F、G。
那么,怎么样才能来保证这个访问的顺序呢?
分析一下,在遍历了根结点后,就开始遍历左子树,最后才是右子树。
因此可以借助堆栈的数据结构,由于堆栈是后进先出的顺序,由此可以先将右子树压栈,然后再对左子树压栈,
这样一来,左子树结点就存在了栈顶上,因此某结点的左子树能在它的右子树遍历之前被遍历。
javascript代码实现
1
2
3
4
5
6
7
8
9
10
|
var dlrAry=[];
function dlr(node){
if(node){
dlrAry.push(node.value);
dlr(node.left);
dlr(node.right);
}
}
dlr(tree);
|
node代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
function tranverse(dir) {
console.log(dir);
var files = fs.readdirSync(dir);
files.forEach(function (file) {
var pathname = path.join(dir,file);
var stat = fs.statSync(pathname);
if(stat.isDirectory()){
tranverse(pathname);
}else{
console.log(pathname);
}
});
};
tranverse("a");
|
递归遍历
觉得用这几个字母表示递归遍历的三种方法不错:
D:访问根结点,L:遍历根结点的左子树,R:遍历根结点的右子树。
先序遍历:DLR
中序遍历:LDR
后序遍历:LRD
顺着字母表示的意思念下来就是遍历的顺序了 ^ ^
这3种遍历都属于递归遍历,或者说深度优先遍历(Depth-First Search,DFS),因为它总
是优先往深处访问。
Javascript代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
var dlrAry=[];
function dlr(node){
if(node){
dlrAry.push(node.value);
dlr(node.left);
dlr(node.right);
}
}
dlr(tree);
console.log('先序遍历:'+dlrAry.join(''));
var ldrAry=[];
function ldr(node){
if(node){
ldr(node.left);
ldrAry.push(node.value);
ldr(node.right);
}
}
ldr(tree);
console.log('中序遍历:'+ldrAry.join(''));
var lrdAry=[];
function lrd(node){
if(node){
lrd(node.left);
lrd(node.right);
lrdAry.push(node.value);
}
}
lrd(tree);
console.log('后序遍历:'+lrdAry.join(''));
|
非递归深度优先遍历
其实对于这些概念谁是属于谁的我也搞不太清楚。有的书里将二叉树的遍历只讲了上面三种递归遍历。有的分广度优先遍历和深度优先遍历两种,把递归遍历都分入深度遍历当中;有的分递归遍历和非递归遍历两种,非递归遍历里包括广度优先遍历和下面这种遍历。个人觉得怎么分其实并不重要,掌握方法和用途就好 :)
刚刚在广度优先遍历中使用的是队列,相应的,在这种不递归的深度优先遍历中我们使用栈。在JS中还是使用一个数组来模拟它。
这里只说先序的:
额,我尝试了描述这个算法,然而并描述不清楚,按照代码走一边你就懂了。
javascript
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
var preOrderUnRecur = function(node) {
if(!node) {
throw new Error('Empty Tree')
}
var stack = []
stack.push(node)
while(stack.length !== 0) {
node = stack.pop()
console.log(node.value)
if(node.right) stack.push(node.right)
if(node.left) stack.push(node.left)
}
}
|
非递归中序
先把数的左节点推入栈,然后取出,再推右节点。
javascript
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
var inOrderUnRecur = function(node) {
if(!node) {
throw new Error('Empty Tree')
}
var stack = []
while(stack.length !== 0 || node) {
if(node) {
stack.push(node)
node = node.left
} else {
node = stack.pop()
console.log(node.value)
node = node.right
}
}
}
|
非递归后序(使用一个栈)
这里使用了一个临时变量记录上次入栈/出栈的节点。思路是先把根节点和左树推入栈,然后取出左树,再推入右树,取出,最后取跟节点。
javascript
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
var posOrderUnRecur = function(node) {
if(!node) {
throw new Error('Empty Tree')
}
var stack = []
stack.push(node)
var tmp = null
while(stack.length !== 0) {
tmp = stack[stack.length - 1]
if(tmp.left && node !== tmp.left && node !== tmp.right) {
stack.push(tmp.left)
} else if(tmp.right && node !== tmp.right) {
stack.push(tmp.right)
} else {
console.log(stack.pop().value)
node = tmp
}
}
}
|
非递归后序(使用两个栈)
这个算法的思路和上面那个差不多,s1有点像一个临时变量。
javascript
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
var posOrderUnRecur = function(node) {
if(node) {
var s1 = []
var s2 = []
s1.push(node)
while(s1.length !== 0) {
node = s1.pop()
s2.push(node)
if(node.left) {
s1.push(node.left)
}
if(node.right) {
s1.push(node.right)
}
}
while(s2.length !== 0) {
console.log(s2.pop().value);
}
}
}
|
Morris遍历
这个方法即不用递归也不用栈实现三种深度遍历,空间复杂度为O(1)(这个概念我也不是特别清楚org)
(这种算法有空再研究)